

Text to image generators
In the summer 2022 we have seen a new trending topic emerging everywhere on the web, which is about AI generated "art" (art, arguably), since the appearance of DALL-E 2 and Craiyon.
This works by typing a prompt in a generator tool, the Artificial Intelligence will then work its way through the visual samples cues it has learned and create a totally new (although inspired from existing material) piece of visual "work".
A lot of people are having fun, sharing their AI collaborative creations on social medias, even a guy named Jason Allen won a digital art contest at the Colorado State Fair.
Many services are available, up until recently, the most popular ones were certainly DALL-E 2 and Midjourney, but Stable Diffusion is adding to the mix, being the only one free and open source ! And simpledit.xyz is all about that.
Stable Diffusion
Any text to image generator needs to be trained on sample visuals, in this case it consisted of more than 2 billions images extracted from the LAION-5B dataset ! I don't know if it's true, but I read somewhere that it costed arounf 600K$ using a supercomputer to train the model weights, making it available to everybody down to a 4GB file. Let's be grateful that computing inferences from this model are as expensive as creating the model itself !
The fact that you can browse the LAION dataset online: https://knn5.laion.ai/ make it easier to choose relevant keywords for your text prompt !
For my early tests, I imagined something along the lines of superman being the winner of a race in the elven city of the lord of the ring (you may ask why, why not ?):
Here is my first batch of results:

Prompt: "Superman running the finishing line of a marathon in the elven city, view from above, eighteenth century oil painting".
WTF right ? These "paintings" sure had to be inspired by the era of the french revolution.
Or is this AI trying to say something about its revolutionary in technology ?
Or even, maybe it is revolted against my prompt ? Ahhhh.
At first, I thought my idea was maybe too complex to manifest properly, out of reach for generating AI art on a local computer ?
But then, I remembered I had seen others generating comparatively complex situations, on reddit and such, and they always mentioned picking from a lot of generations and refining their prompts.
So keeping this in mind I really wanted the emphasis on Superman winning the race, I used the LAION search engine and I tried to search the terms "finishing line", I could see it was really not the mood intended, because in this image database, those keywords are relating mostly to children drawings and even pastery.
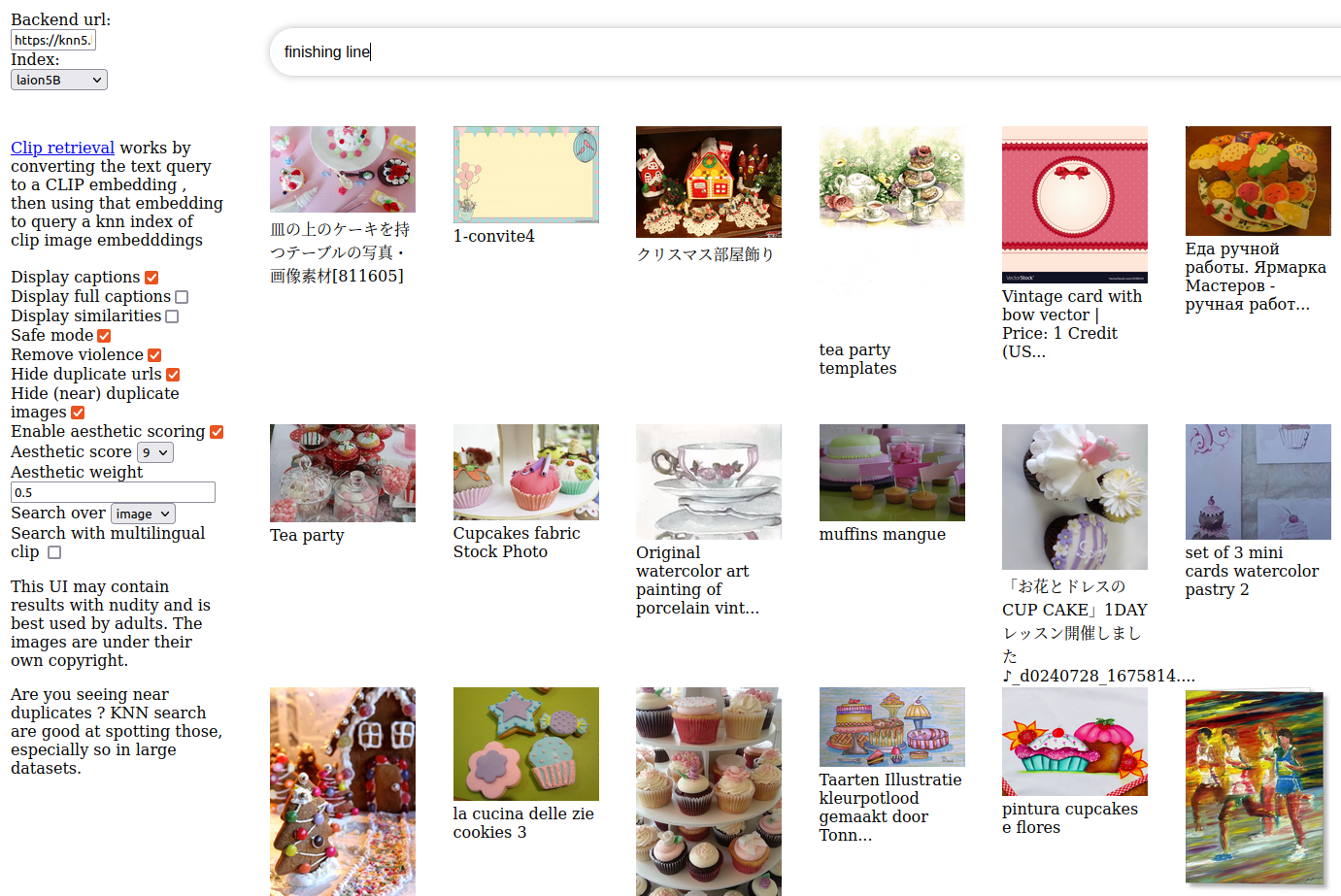
I then tried alternative wording to be sure it could at least approach the frame and context idea and I got better search results with keywords such as "athlete runner winning olympics like usain bolt".

Prompt: "lord of the ring, athlete runner winning finish line, olympic games in rivendell, winning runner like usain bolt, 18th oil painting"

Now I had the style right, but I was missing the superman protagonist and the elves city context, so I repeated the search process in LAION database, the good thing about it is that you can click on the magnifier any of the results and you the search string will be updated accordingly so the refining process is quite organic.
After some browsering, I found out a more efficient replacement for even city was rivendell elven city, elvish kingdoms with the keywords fantasy landscape scenery.
Now results were starting to be way more satisfying:

Prompt: "lord of the ring athlete runner winning finish line, olympic games in rivendell elven city, elvish kingdoms, winning runner like superman, 18th oil painting fantasy landscape scenery, lord of the rings background"
Tweaking SD parameters
I use SD (Stable Diffusion) on the Ubuntu 20.04 LTS linux release, with command lines, where you can tweak the output rendering process with arguments.
First you may want to start with a max resolution of 512 to produce faster results, and then increase your best generation resolution later on, using the same seed (more on that below)
Arguments for dimensions are --H 512 --W 512 H for width and W for width, they don't have to form a square. I found out I could still generate a 4 or 5 images at 1028 x 767 in a few minutes (around 5min and under 10min) on my mobile graphic card 6GB 3060 RTX.
Another interesting parameter is ddim_steps, it represents the number of passes before the image is done, the default value is 50. If you put too much steps it will take a very long time without quality improvement, if this parameters is too low the image won't be meaningful at all and will resemble a noisy patch of pixels, like artifacts.
--ddim_steps 50
The n_samples option quantifies how many image outputs you want to be produced. I would advise that you always start with 1 to 3 samples so that you get the mood of your generation without loosing too much time.
--n_samples 5
Those parameters are most basic, now many fork projects extends the original SD and adds optimizations to it.
My favorite SD fork of choice is https://github.com/basujindal/stable-diffusion, it will lower the VRAM usage so you can use it even on a RTX laptop and also allows other cool features such as weighting keywords in your prompt.
python optimizedSD/optimized_txt2img.py --prompt "lord of the ring athlete runner winning finish line, olympic games in rivendell elven city, elvish kingdom, winning runner like superman, 18th oil painting fantasy landscape scenery, lord of the rings background" --H 512 --W 512 --ddim_steps 50 --n_samples 6 --turbo
Note that I am using the python script replacement from the fork above, accessed from the optimizedSD directory instead of the ./scripts one.
Seeds and iterations and upscaling
Seeds
When you want to reproduce one generation to get similar results, use the same seed of "inspiration", for instance to increase its steps or resolution of a generation from a previous prompt: there is a --seed parameter, which random by default. Theoretically, one could try to reproduce similar generation results on a different computer and at different times, using the same model.ckpt and seed.
Thankfully you can easily find the seed for an image in its filename. It is followed by a number suffix such as _00000X in case you have made multiple iteration over that seed.
python optimizedSD/optimized_txt2img.py --prompt "lord of the ring athlete runner winning finish line, olympic games in rivendell elven city, elvish kingdom, winning runner like superman, 18th oil painting fantasy landscape scenery, lord of the rings background" --H 512 --W 512 --ddim_steps 250 --n_samples 1 --seed 291893 --turbo
Funny things can happen when you add more steps to iterate over one seed. Take this generation from the previous superman runner prompt, for instance, at 250 steps it starts getting its shirt off, nobody knows if would be NSFW at 1000+ steps. Maybe AI have a sense of humor after all ...
AI generated content


Upscaling
Once you're done with your seed of choice and its iterations, consider using a separate tool / algorithm if you want to get a high resolution, since there is a hard limit of what you can get through the W and H txt2img's parameters. Indeed, the resolution is very much using VRAM resources and it will peak at some point.
In another article, I wrote about some upscalers available through your web browser. One of the most efficient project for this is called real-ESRGAN.
Another one called GFPGAN is espacially optimized for upscaling faces, and you can even use it in combination with the ESRGAN above.
Use them here will it last: https://replicate.com/xinntao/realesrgan
Or install them on your local computer from source:
- Multi purpose general upscaler: https://github.com/xinntao/Real-ESRGAN
- Face recognition upscaler: https://github.com/TencentARC/GFPGAN
Note that GFPGAN will add much details to a face, but not to its surrounding environment.
Generating from another image
The next cool script shipping with Stable Diffusion is img2img, namely, you can use it to transform your sketches to more advanced creations.
Don't get fooled by what you see on social medias, in order to run a convincing inference, it's way harder than it seems to actually get a good matching prompt with a childish sketch...
From the basujindal/stable-diffusion fork, use the optimizedSD/optimized_img2img.py script such as:

Prompt: "Painting of a classy elephant, wearing a tuxedo, james bond style, designer architect house, miami_80s sunset, behance winner" (Believe me the other results are not worth showing xD).
As you can see, I struggle to get good results using this method.
There is an interesting additional argument called strength that you can use with img2img in order to adjust how much of the original input image you want to keep, the lower (0), the closer to the original, maximum is 1.
It is possible to use previously AI generated content as a feedback to itself and iterate over selected piece of content, this is when the strengh argument comes in handy to specify an rough amount of what you want to preserve from the input image.
Given all that we have seen so far, I took note of my favored seed from the superman marathon prompt above, fed it the infered image that I liked as an input image and expanded on it with 500 steps and slightly higher resolution.
Here is the command line I used:
python optimizedSD/optimized_img2img.py --init-img '/home/didier/AIrepos/stable-diffusion/outputs/txt2img-samples/lord_of_the_ring_athlete_runner_winning_finish_line,_olympic_games_in_rivendell_elven_city,_elvish_kingdoms,_winning_runner_li/seed_29189300002_00007.png' --prompt "lord of the ring athlete runner winning finish line, olympic games in rivendell elven city, elvish kingdoms, winning runner like superman, 18th oil painting fantasy landscape scenery, lord of the rings background" --H 768 --W 512 --ddim_steps 500 --n_samples 1 --seed 2918930002


Click on the above double fading background to see how the strength parameter affected the inference.
Notice how I only needed 1 sample this time.
It took 2 min 25 seconds to complete on my rtx 3006 mobile, with the optimized --turbo argument (vs 6min 51 seconds without).
Conclusion
AI image generation can be fun but also time consuming, not only because it takes more or less time to generate enough content until you get good one, but also time to setup and to research good prompts. Of course this is nothing compared to the time needed to craft an original piece of work without being assisted with AI, nonetheless, most of the time the outputs are very far from a work done by a human being taking a photograph or painting.
In the past,people have complained about photography when it appeared, because they said it would replace painting, then the same happened when home computers became a reality and the digital era took over photography and painting. However, each craft has its own visual touch, and as much as it happened with digital painting and digital photography, old methods of creating arts never disappeared even if they maybe became somehow less popular, they are different and are still relevant today. Right now AI generated imagery is nothing like work done by humans and these are limited to fixed datasets of visual samples, plus, the output is not devoid of style in the sense that a trained eye can recognize patterns specific to AI image generators outputs (rounded edges, oddities in limbs and many more incoherencies).
Maybe one day in a distant future it will become more difficult to say what has been done by who ? If this is meant to happen, my bet is that we are decade away from it, and AI alone will not be able to generate a good original prompt until they find a way to engage in a discussion with an AI, that is to say, there will always be a sort of collaboration with creative directors.
If you want an authentic artist point of view about collaboration, I suggest you to watch James Gurney video where he explore some prompts and compare this process with human collaboration.
References:
- https://huggingface.co/blog/stable_diffusion
- https://arxiv.org/pdf/2112.10752.pdf
- https://andys.page/posts/how-to-draw/#
- https://www.reddit.com/r/StableDiffusion/comments/x0nnfr/another_stunning_img2img_example/
- https://github.com/CompVis/stable-diffusion
- https://www.reddit.com/r/StableDiffusion/comments/x6imyf/princess_peach/